In the summer of 2017, a team of Google Mind researchers quietly released a paper that would certainly for life change the trajectory of artificial intelligence. Titled “Focus Is All You Required,” this scholastic magazine really did not get here with splashy keynotes or frontpage information. Instead, it debuted at the Neural Data Processing Solution (NeurIPS) conference, a technical event where cutting-edge ideas frequently simmer for many years prior to they reach the mainstream.
Couple of outside the AI research area understood it at the time, yet this paper would certainly prepare for almost every significant generative AI design you’ve come across today from OpenAI’s GPT to Meta’s LLaMA variants, BERT, Claude, Poet, you name it.
The Transformer is an innovative semantic network architecture that sweeps away the old presumptions of sequence processing. As opposed to linear, step-by-step handling, the Transformer embraces a parallelizable device, secured in a method known as self-attention. Over an issue of months, the Transformer revolutionized how equipments comprehend language.
A New Version
Prior to the Transformer, cutting edge natural language handling (NLP) pivoted heavily on recurring semantic networks (RNNs) and their refinements– LSTMs (Lengthy Short-Term Memory networks) and GRUs (Gated Recurrent Devices). These recurring neural networks refined message word-by-word (or token-by-token), passing along a covert state that was indicated to encode everything checked out up until now.
This process felt intuitive … after all, we checked out language from delegated right, so why should not a model?
Yet these older designs came with essential shortcomings. For one, they had problem with very long sentences. By the time an LSTM reached completion of a paragraph, the context from the get go frequently seemed like a faded memory. Parallelization was likewise difficult since each action relied on the previous one. The area desperately required a means to process sequences without being embeded a direct rut.
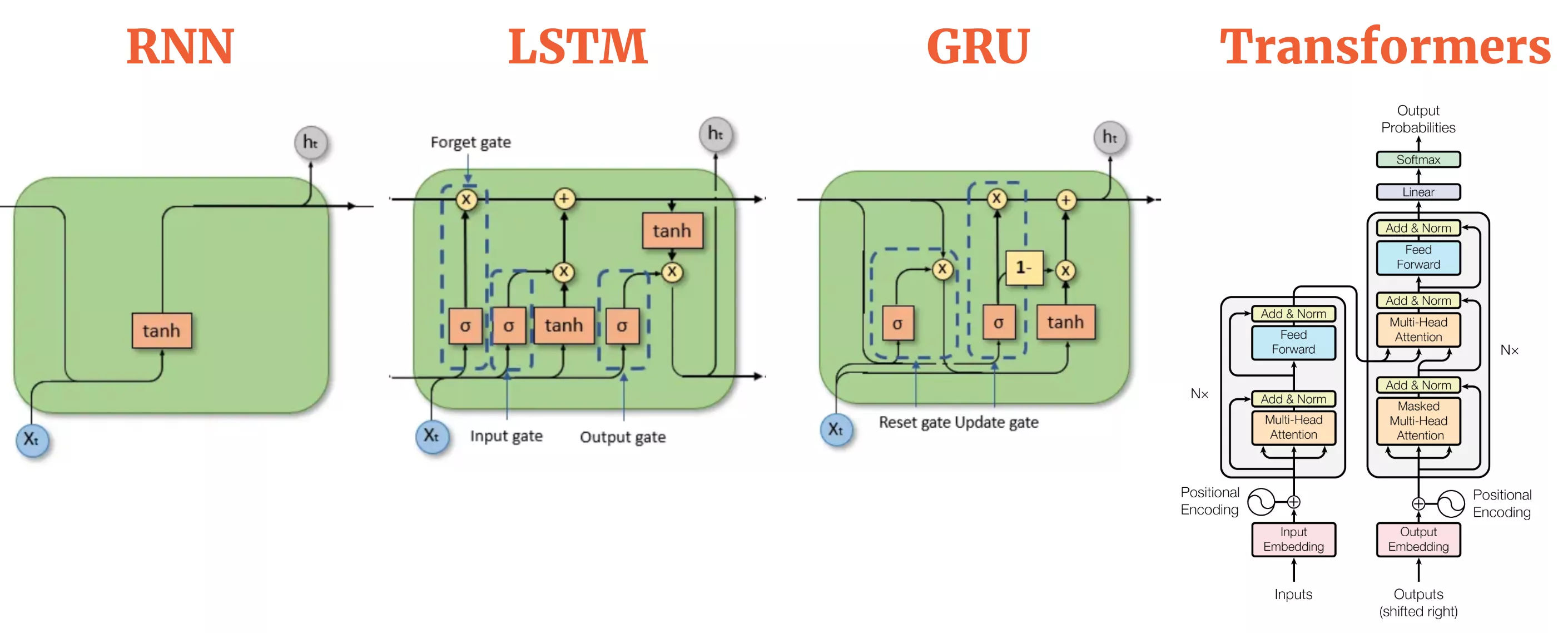
Google Brain scientists laid out to change that vibrant. Their option was stealthily simple: ditch recurrence entirely. Rather, they created a version that could look at every word in a sentence at the same time and figure out exactly how each word pertaining to every various other word.
This creative trick– called the “interest system”– allow the model focus on the most appropriate components of a sentence without the computational baggage of reoccurrence. The outcome was the Transformer : quickly, parallelizable, and bizarrely efficient managing context over lengthy stretches of message.
The breakthrough idea was that “focus,” not sequential memory, could be truth engine of understanding language. Interest devices had existed in earlier designs, but the Transformer raised attention from a sustaining function to the star of the show. Without the Transformer’s full-attention framework, generative AI as we know it would likely still be embeded slower, more limited standards.

But exactly how did this concept happened at Google Mind? The backstory is sprayed with the sort of blessing and intellectual cross-pollination that defines AI research study. Insiders talk about informal conceptualizing sessions, where researchers from different teams compared notes on how attention mechanisms were assisting resolve translation jobs or boost placement between source and target sentences.
There were coffee-room debates over whether the requirement of reappearance was just an antique of old reasoning. Some scientists recall “hallway training sessions” where a then-radical idea– getting rid of RNNs totally– was drifted, tested, and refined before the group finally chose to dedicate it to code.
Part of the sparkle of the transformer is that it made it feasible to educate on significant datasets extremely rapidly and successfully.
The Transformer’s design utilizes two almosts all: an encoder and a decoder. The encoder refines the input data and produces a comprehensive, purposeful representation of that information utilizing layers of self-attention and simple neural networks. The decoder functions likewise but focuses on the previously created result (like in message generation) while likewise using info from the encoder.
Component of the sparkle of this style is that it made it possible to train on significant datasets really promptly and effectively. An oft-repeated anecdote from the early days of the Transformer’s development is that some Google engineers really did not at first recognize the extent of the version’s capacity.
They recognized it was good– much better than previous RNN-based models at particular language tasks– but the concept that this can change the entire field of AI was still unfolding. It had not been until the style was publicly launched and enthusiasts worldwide started trying out that real power of the Transformer came to be obvious.
A Renaissance in Language Designs
When Google Mind published the 2017 paper, the NLP neighborhood reacted initially with curiosity, after that with astonishment. The Transformer architecture was seen outperforming the very best machine translation versions at jobs like the WMT English-to-German and English-to-French standards. Yet it wasn’t simply the efficiency– scientists rapidly recognized the Transformer was orders of size much more parallelizable. Training times plunged. Suddenly, jobs that as soon as took days or weeks could be performed in a portion of the moment on the same hardware.
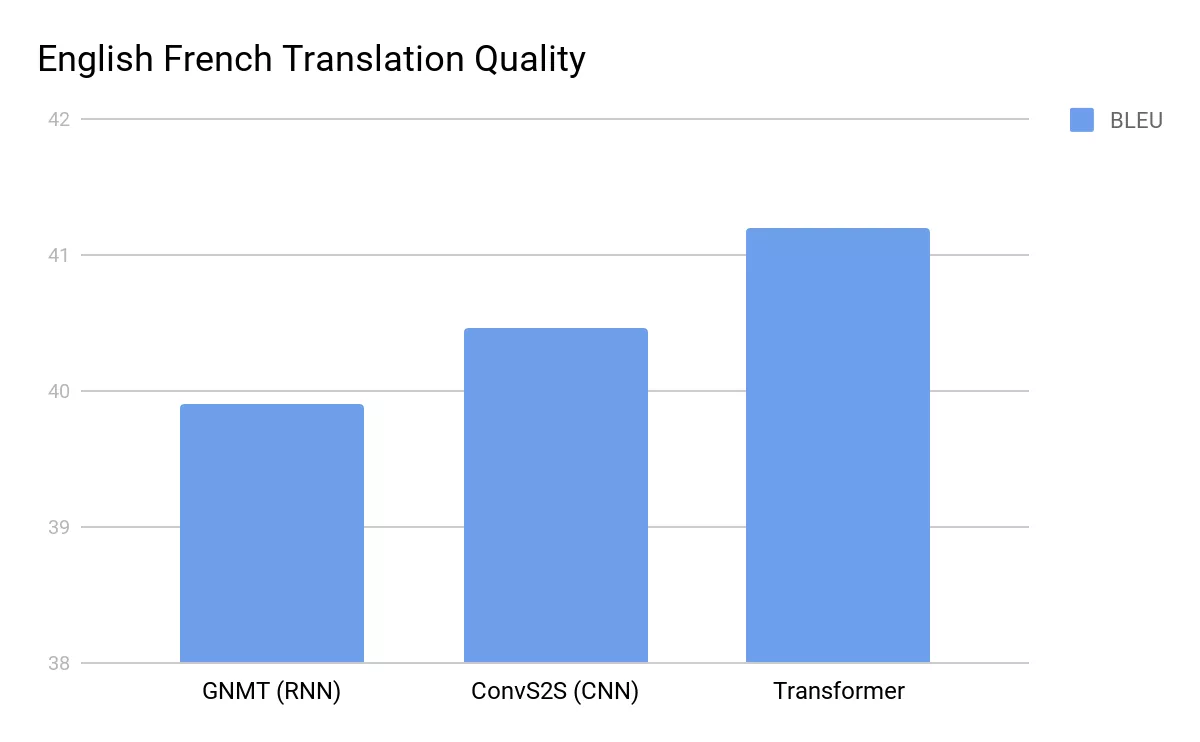

Within a year of its introduction, the Transformer model had actually motivated a wave of developments. Google itself leveraged the Transformer architecture to develop BERT (Bidirectional Encoder Depictions from Transformers). BERT significantly boosted the means machines recognized language, taking the leading spot on lots of NLP criteria. It soon found its means right into everyday items like Google Look, quietly improving exactly how queries were analyzed.
Media outlets found GPT’s expertise and showcased numerous examples– often jaw-dropping, in some cases happily off-base.
Virtually at the same time, OpenAI took the Transformer blueprint and went in another instructions with GPT (Generative Pre-trained Transformers).
GPT- 1 and GPT- 2 meant the power of scaling. By GPT- 3, it became difficult to neglect exactly how great these systems went to generating human-like text and reasoning with complex motivates.
The initial ChatGPT variation (late 2022 utilized a further refined GPT- 3 5 model, it was a watershed moment. ChatGPT might generate strangely coherent text, equate languages, write code snippets, and even generate poetry. All of a sudden, a device’s capability to generate human-like message was no longer a wishful thinking yet a tangible fact.

Media outlets found GPT’s prowess and showcased many examples– occasionally jaw-dropping, in some cases happily off-base. The general public was both thrilled and agitated. The idea of AI-assisted creativity moved from science fiction to everyday discussion. This wave of progress– fueled by the Transformer– changed AI from a specialized device into a general-purpose reasoning engine.
But the Transformer isn’t just proficient at message. Scientists found that focus mechanisms can function throughout various sorts of information– images, music, code.
However the Transformer isn’t just good at text. Researchers discovered that interest systems could function throughout different types of data– images, music, code. Soon, versions like CLIP and DALL-E were mixing textual and aesthetic understanding, producing “one-of-a-kind” art or labeling photos with incredible precision. Video understanding, speech recognition, and also scientific data evaluation began to take advantage of this very same underlying blueprint.
On top of that, software program structures like TensorFlow and PyTorch incorporated Transformer-friendly building blocks, making it much easier for enthusiasts, start-ups, and market laboratories to experiment. Today, it’s not uncommon to see specialized variants of the Transformer design turn up in every little thing from biomedical research to economic forecasting.
The Race to Larger Designs
A crucial discovery that became researchers continued to press Transformers was the principle of scaling legislations. Experiments by OpenAI and DeepMind found that as you raise the number of specifications in a Transformer and the size of its training dataset, efficiency remains to boost in a predictable way. This linearity came to be an invitation for an arms race of types: larger models, more data, more GPUs.
Experiments found that as you enhance the number of criteria in a Transformer and the dimension of its training dataset, efficiency remains to improve in a foreseeable way … this linearity ended up being an invite for an arms race of kinds: larger designs, more data, even more GPUs.
Google, OpenAI, Microsoft, and several others have poured tremendous sources into building enormous Transformer-based versions. GPT- 3 was complied with by even bigger GPT- 4, while Google introduced designs like hand with hundreds of billions of specifications. Although these enormous designs produce more fluent and experienced results, they also increase new questions about cost, performance, and sustainability.

Training such designs eats huge computer power (Nvidia is also satisfied about that a person) and electrical power– transforming AI research right into a venture that is a lot more detailed today to commercial engineering than the scholastic dabbling it once was.
Attention Anywhere
ChatGPT has become a social phenomenon, bursting out of technology circles and sector conversations to stimulate dinner table discussions about AI-generated web content. Even people who aren’t tech-savvy now have some understanding that “there’s this AI that can create this for me” or speak to me “like a human.” On the other hand, secondary school trainees are significantly turning to GPT queries as opposed to Google or Wikipedia for answers.
However all technological changes come with side effects, and the Transformer’s influence on generative AI is no exception. Even at this early stage, GenAI versions have actually ushered in a brand-new period of artificial media, elevating complicated concerns concerning copyright, false information, actings of somebodies, and honest deployment.
The exact same Transformer models that can produce well human prose can also generate misinformation and poisonous outputs. Biases can and will certainly exist in the training data, which can be discreetly embedded and enhanced in the responses offered by GenAI models. Consequently, governments and regulatory bodies are beginning to pay very close attention. Exactly how do we make sure these designs don’t end up being engines of disinformation? Exactly how do we shield intellectual property when designs can generate message and photos as needed?
https://www.youtube.com/watch?v= 11 zl 08 qpDWc
Researchers and the business establishing today’s dominant designs have begun to incorporate justness checks, establish guardrails, and focus on the liable implementation of generative AI (approximately they state). Nonetheless, these efforts are unfolding in a dirty landscape, as considerable inquiries remain concerning exactly how these versions are trained and where big technology companies resource their training information.
The “Attention Is All You Need” paper continues to be a testimony to exactly how open research can drive global technology. By releasing all the vital details, the paper allowed any individual– competitor or partner– to build on its ideas. That spirit of openness by Google’s group, sustained the astonishing rate at which the Transformer design has actually spread out across the market.
We are just beginning to see what takes place as these versions come to be more specialized, extra efficient, and more commonly available. The equipment learning area remained in dire demand for a version that could handle complexity at range, and self-attention thus far has delivered. From maker translation to chatbots that can carry on diverse conversations, from photo classification to code generation. Transformers have actually come to be the default foundation for all-natural language processing and after that some. Yet researchers are still questioning: is focus genuinely all we need?

New designs are currently emerging, such as Performer, Longformer, and Agitator, intending to improve the efficiency of interest for long series. Others are experimenting with crossbreed methods, combining Transformer blocks with other specialized layers. The area is anything however stagnant.
Moving on, each new proposition will gather examination, excitement, and why not, anxiety.